math 개념
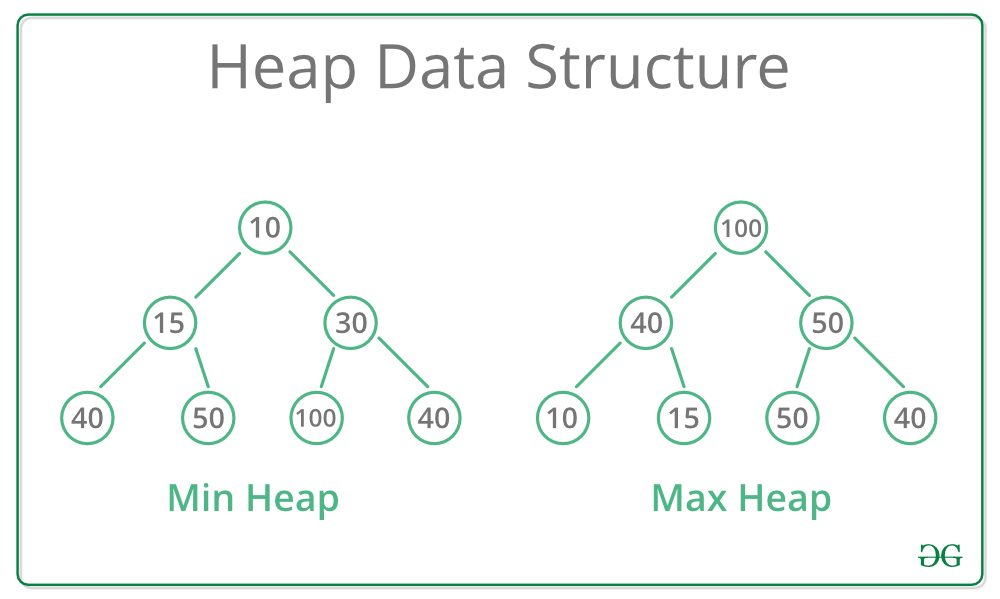
힙은 특정한 규칙을 가지는 트리로, 최댓값과 최솟값을 찾는 연산을 빠르게 하기 위해 고안된 완전이진트리를 기본으로 한다.
힙 property : A가 B의 부모노드이면 A의 키값과 B의 키값 사이에는 대소 관계가 성립한다
heapq.heappush(heap, item)
힙 불변성을 유지하면서, item 값을 heap으로 푸시합니다.
heapq.heappop(heap)
힙 불변성을 유지하면서, heap에서 가장 작은 항목을 팝하고 반환합니다.
힙이 비어 있으면, IndexError가 발생합니다. 팝 하지 않고 가장 작은 항목에 액세스하려면,
heap[0]을 사용하십시오.
heapq.heappushpop(heap, item)
힙에 item을 푸시한 다음, heap에서 가장 작은 항목을 팝하고 반환합니다.
결합한 액션은 heappush()한 다음 heappop()을 별도로 호출하는 것보다 더 효율적
heapq.heapify(x)
리스트 x를 선형 시간으로 제자리에서 힙으로 변환합니다.
heapq.heapreplace(heap, item)
heap에서 가장 작은 항목을 팝하고 반환하며, 새로운 item도 푸시합니다.
힙 크기는 변경되지 않습니다. 힙이 비어 있으면, IndexError가 발생합니다.
이 한 단계 연산은 heappop()한 다음 heappush()하는 것보다 더 효율적이며
고정 크기 힙을 사용할 때 더 적합 할 수 있습니다. 팝/푸시 조합은
항상 힙에서 요소를 반환하고 그것을 item으로 대체합니다.
반환된 값은 추가된 item보다 클 수 있습니다. 그것이 바람직하지 않다면,
대신 heappushpop() 사용을 고려하십시오. 푸시/팝 조합은 두 값 중 작은 값을 반환하여,
힙에 큰 값을 남겨 둡니다.
이 모듈은 또한 힙 기반의 세 가지 범용 함수를 제공합니다.
heapq.merge(*iterables, key=None, reverse=False)
여러 정렬된 입력을 단일 정렬된 출력으로 병합합니다
(예를 들어, 여러 로그 파일에서 타임 스탬프 된 항목을 병합합니다).
정렬된 값에 대한 이터레이터를 반환합니다.
sorted(itertools.chain(*iterables))와 비슷하지만 이터러블을 반환하고,
데이터를 한 번에 메모리로 가져오지 않으며, 각 입력 스트림이 이미 (최소에서 최대로)
정렬된 것으로 가정합니다.
키워드 인자로 지정해야 하는 두 개의 선택적 인자가 있습니다.
key는 각 입력 요소에서 비교 키를 추출하는 데 사용되는 단일 인자의 키 함수를 지정합니다.
기본값은 None입니다 (요소를 직접 비교합니다).
reverse는 불리언 값입니다. True로 설정하면, 각 비교가 반대로 된 것처럼
입력 요소가 병합됩니다. sorted(itertools.chain(*iterables), reverse=True)와
유사한 동작을 달성하려면 모든 이터러블이 최대에서 최소로 정렬되어 있어야 합니다.
버전 3.5에서 변경: 선택적 key와 reverse 매개 변수를 추가했습니다.
heapq.nlargest(n, iterable, key=None)
iterable에 의해 정의된 데이터 집합에서 n 개의 가장 큰 요소로 구성된 리스트를 반환합니다.
key가 제공되면 iterable의 각 요소에서 비교 키를 추출하는 데 사용되는 단일 인자 함수를
지정합니다 (예를 들어, key=str.lower). 다음과 동등합니다:
sorted(iterable, key=key, reverse=True)[:n].
heapq.nsmallest(n, iterable, key=None)
iterable에 의해 정의된 데이터 집합에서 n 개의 가장 작은 요소로 구성된 리스트를 반환합니다.
key가 제공되면 iterable의 각 요소에서 비교 키를 추출하는 데 사용되는 단일 인자 함수를
지정합니다 (예를 들어, key=str.lower). 다음과 동등합니다:
sorted(iterable, key=key)[:n].
마지막 두 함수는 작은 n 값에서 가장 잘 동작합니다. 값이 크면,
sorted() 기능을 사용하는 것이 더 효율적입니다. 또한, n==1일 때는,
내장 min()과 max() 함수를 사용하는 것이 더 효율적입니다.
이 함수를 반복해서 사용해야 하면, iterable을 실제 힙으로 바꾸는 것이 좋습니다.
nlargest(n, heap)
함수는 n개의 가장 큰 값들로 이루어진 리스트를 반환한다.
즉, 첫번째 인자에 찾고싶은 최대값의 개수를 넣어주면 됨!!